
Obsidian索引だけをAIに読ませる運用にした理由
AI自動化は、動かし始めた瞬間よりも、数日後に修正するときに設計の差が出る。私は最近、Obsidian Vault全体をAIへ読ませる運用をやめ、agent indexで選んだ短い索引だけを渡し、必要なノートだけ追加で読む構成へ変更した。対象は、1日1本の記事生成、候補最大3件、画像最低2枚を固定条件にしたブログ運用だ。
使った道具はObsidian、Codex、agent index。参照元は content/instagram_growth_daily/story_daily/story_daily_status.json や publish_bundle.json など、実際に必要なログへ絞った。目的は大量生成ではなく、「必要な情報だけ安全に読ませる」状態を作ることだった。特に、長期運用時の修正負荷と、不要情報の混入を減らしたかった。
この記事では、Vault全体をAIへ渡した時に起きた失敗、索引方式へ切り替えた理由、実際に変えた運用、公開前の停止条件までをまとめる。同じように個人ブログや小規模メディアをAIで運用したい人が、読む範囲を小さくしながら長期継続できるように、実測、失敗、判断基準、修正しやすさを中心に整理する。
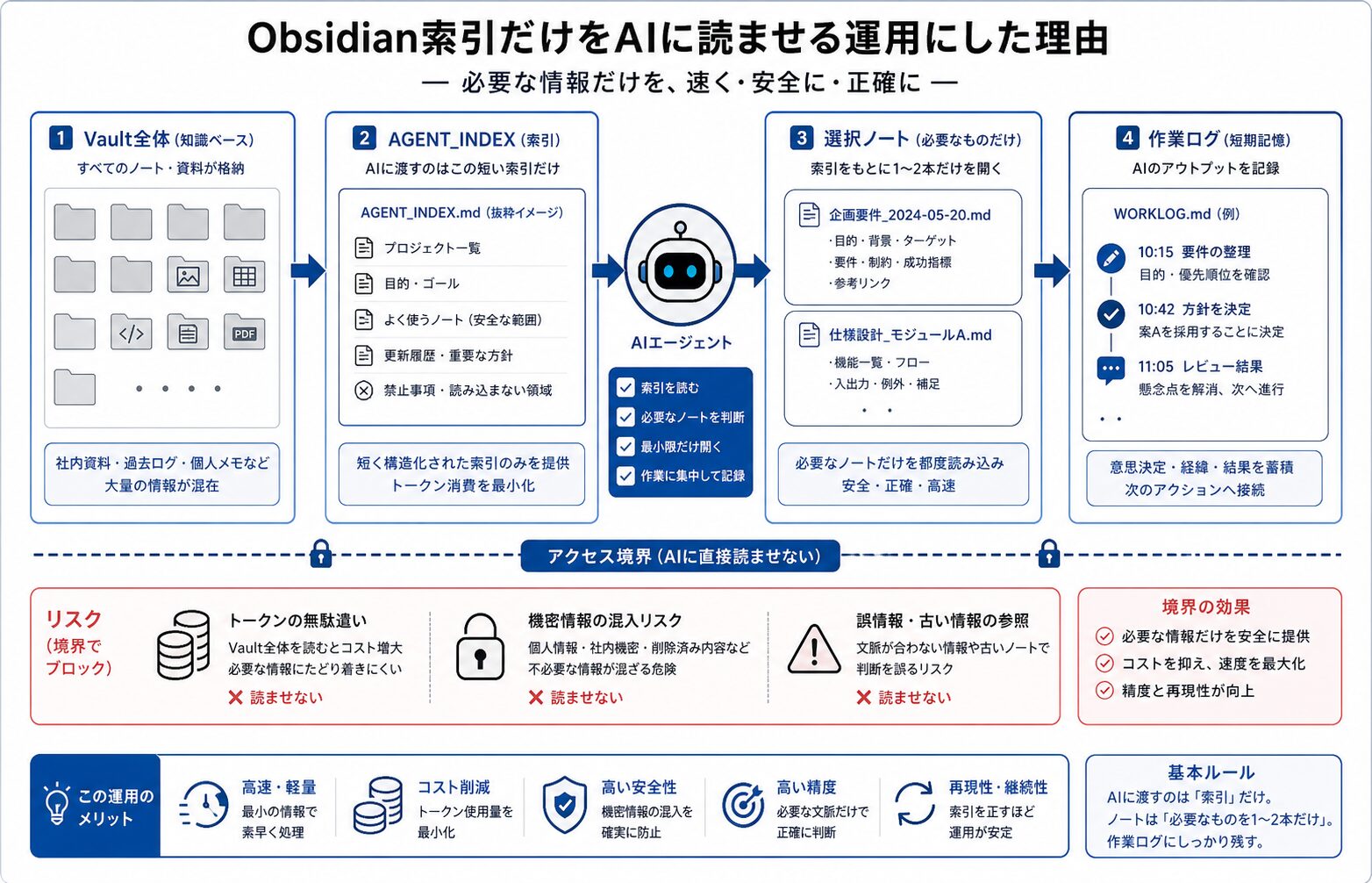
Vault全体を読ませた時に起きた問題
最初の頃は、Obsidian Vault全体をAIへ読ませるほうが便利だと思っていた。過去の記事案、投稿ログ、画像メモ、検証ログ、構想メモまで全部を渡せば、AIが長期記憶として扱えると考えていたからだ。
ただ、数日運用すると問題が出始めた。特に大きかったのは、記事の焦点がズレることだった。本来は「Instagramストーリー投稿の状態管理」を書く予定なのに、過去の別メモを拾って一般論へ流れたり、別テーマの記事案へ引っ張られたりする。タイトルと本文の方向がズレるため、読者から見ると「結局何の記事なのか」が途中で分からなくなる。
もう一つ大きかったのは、トークン消費だった。Vault全体を毎回読む構成は、情報量が増えるほど読み込みコストも増える。特に画像生成ログや検証メモが蓄積すると、必要情報より不要情報のほうが多くなる。結果として、本文の密度は下がるのに、読み込み量だけ増えていった。
実際、同じ1本の記事生成でも、必要ログだけを読む方式に変えた後は、読み込み対象がかなり小さくなった。特に story_daily_status.json、publish_bundle.json、live_post_result.json を中心にした構成では、「今必要な情報」が明確になり、本文の脱線が減った。
さらに危険だったのは、関係ないメモまで混ざることだった。公開用ではない途中メモ、没案、比較途中の文章までAIが拾うと、本文へ不要な文脈が混ざる。自動化は便利だが、「読ませすぎる」と制御しにくくなる。ここは想像以上に大きかった。
だから私は、「AIへ全部覚えさせる」のではなく、「必要な記憶だけ選んで読ませる」方向へ設計を変えた。
agent indexを入口にした理由
今回の変更で中心になったのが、agent indexを入口にする構成だった。
やったこと自体は単純で、Vault全体を直接読ませるのではなく、「今回の作業で読む候補」を短い索引として先に渡す。そこから必要なノートだけ追加で読む。つまり、AIが最初に見る情報量を意図的に小さくした。
今回の運用では、主に以下のようなファイルへ絞った。
story_daily_status.json
publish_bundle.json
live_post_result.json
story_365_manifest.json
これだけでも、投稿状態、画像生成、公開結果、管理状況は追える。逆に、過去の構想メモや別テーマの記事案は不要だった。
この方式にしてから、記事の主題がかなり安定した。タイトルで「Obsidian索引だけをAIに読ませる運用」と書いたなら、本文もその話へ戻りやすくなる。Vault全体を読んでいた頃は、途中で別テーマへ脱線しやすかったが、入口を狭くすると構成が崩れにくい。
改善しやすかった点も大きい。もし記事品質が落ちた場合でも、「索引が悪いのか」「参照ノート選択が悪いのか」「本文構成が悪いのか」を切り分けやすい。全部を読む構成だと、どの情報が悪影響だったのか追跡できなかった。
毎日運用では、「AIが賢いか」より、「原因を追跡できるか」のほうが重要だった。
本文生成で役割を分けた
今回の運用で特に意識したのは、「事実整理」と「本文生成」を分けることだった。
Codex側では、完成原稿を作らない。代わりに、次の情報だけを短く整理する。
何を試したか
なぜその設計にしたか
固定した数字
どこで失敗したか
次に何を改善するか
今回なら、「1日1本」「候補最大3件」「画像最低2枚」という固定条件がそれにあたる。
逆に、本文全体の読みやすさや章構成はGPT Web Pro側へ寄せた。ここを分けないと、きれいだが中身の薄い記事になりやすい。特にAI記事は、導入だけ整っていて、実測値や失敗が抜ける状態になりやすかった。
実際、最初の頃は失敗した。文章生成へ全部任せると、構成は整うが、「なぜその設計なのか」が消える。例えば「画像最低2枚」という条件も、単なるルールとしてしか残らない。本当は、「本文だけだと後から読み返しにくい」「要約図がないと全体を思い出しにくい」という理由がある。
だから私は、ローカル側では事実密度を優先するように変えた。公開品質の文章は後から整えられるが、実測、失敗、原因、修正理由は後から作れない。ここを分離したことで、記事全体の再現性がかなり上がった。
特に効果が大きかったのは、「読者が真似できる点」を必ず先に整理することだった。単なるログの言い換えではなく、「次の人が同じ環境で再現できるか」を軸にすると、本文の方向が安定しやすい。
止める条件を先に作った
今回の設計変更で最も効果があったのは、「公開する条件」より先に、「止める条件」を定義したことだった。
毎日投稿では、「生成できるか」だけを見ると危険だった。むしろ重要なのは、「低品質な記事を止められるか」だった。
実際に入れた停止条件はかなり単純だ。
タイトル重複なら止める
H2不足なら止める
実測や失敗が無ければ止める
画像2枚未満なら止める
秘密情報が混ざれば止める
タイトルと本文がズレたら止める
これを先に定義してから、記事生成を回す形へ変えた。
以前は、「生成できたから公開する」状態だった。ただ、その運用だと、同じテーマの記事が増えたり、読者が真似できない記事が混ざったりする。短期的には投稿数が増えても、長期ではブログ全体の信頼を削る。
特に危険だったのは、「内部ログを言い換えただけの記事」だった。作業者目線では具体的に見えるが、読者目線では価値が薄い。だから最近は、「読者が自分の環境で試せるか」を公開条件へ入れている。
自動化を増やすより、停止条件を増やしたほうが安定した。ここは実運用でかなり差が出た。
読む範囲を小さくすると修正しやすい
Vault全体読み込みをやめて分かったのは、「読む範囲が小さいほど修正しやすい」ということだった。
例えば、記事生成で失敗した場合でも、今は確認範囲がかなり狭い。
最初にagent indexを見る。次に選択ノートを見る。最後に本文を見る。この3段階だけで原因を追える。
以前のようにVault全体を渡していた頃は、「どのメモが影響したか」が分からなかった。結果として、修正時に全部を見返す必要があり、毎回の確認コストが高かった。
今は、「入口を狭くする」こと自体が品質管理になっている。
さらに、作業ログも残しやすくなった。今回なら story_daily_status.json や live_post_result.json のように、読むファイルを固定しているので、後から「なぜこの設計だったか」を追いやすい。
AI自動化は、最初に動かすことより、「翌週も説明できる状態を維持すること」のほうが難しい。特に毎日投稿では、昨日の判断理由を翌週に説明できないと、修正時に破綻する。
そのため私は、長期記憶を広げるより、「毎回どこを読むか」を固定する方向へ寄せた。読む境界を先に決めるほうが、安全性、再現性、修正速度の全部が安定した。
画像を要約図として使う
ブログ記事はテキストだけでも成立する。ただ、この運用では画像を単なる飾りとして扱わない。
今回なら、「Vault全体」「agent index」「選択ノート」「本文生成」「公開ログ確認」の境界を図として整理する。読者が本文を全部読み返さなくても、「何をどの順番で見る設計なのか」を思い出せる状態を作る。
特に毎日運用では、後から読み返す回数が多い。その時に、本文を全部読み直さなくても、要約図で流れを確認できる構成はかなり効いた。
また、画像最低2枚という条件も、この運用から決めた。1枚は記事入口としてのサムネイル、もう1枚は本文要約として使う。画像を増やすより、「どの情報を整理する画像なのか」を先に決めたほうが安定した。
ただし、画像は本文の代わりにはならない。画像だけがきれいで、本文に実測や失敗が無い記事は弱い。あくまで本文に読者価値があり、その理解を短くするために画像を置く。
ここを逆転させないことは、毎日投稿でかなり重要だった。
真似するならこう進める
同じ運用を試すなら、最初にVault全体を読ませないことをおすすめする。
まず、今の作業で必要な情報だけを候補最大3件程度へ絞る。次に、その索引だけをAIへ渡す。必要になった時だけ追加ノートを読む。
そのうえで、本文前に次の5点を整理する。
何を試したか
なぜその設計にしたか
固定した数字
失敗やリスク
読者が真似できる点
その後に、導入、背景、失敗、改善、手順、まとめの順で本文を組む。これだけでも、話題がかなりズレにくくなる。
重要なのは、「AIへ全部覚えさせる」発想をやめることだった。毎回読む範囲を小さくし、必要な情報だけ選ぶほうが、安全で修正しやすい。
長期記憶を広げるより、「読む境界を固定する」。今回の運用変更で、一番残ったのはこの感覚だった。
公開前チェック
冒頭3段落で実験内容が分かるか
H2が主題へ戻っているか
実測、失敗、原因、対処が入っているか
読者が真似できる手順があるか
画像2枚前提で構成されているか
タイトルと本文の焦点がズレていないか
不要なVault情報が混ざっていないか
読む範囲の境界が説明できるか